RK3588 yolov10精度问题&硬件加速
问题描述
最近训练了pt文件(yolo),通过瑞芯微提供的框架转换成了onnx 官方提供的ultralytics:
1.置信度分支添加sigmoid算子
2.移除后处理结构,
3.移动dfl结构到模型外部
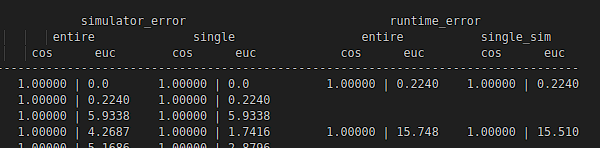
因此三个检测头变成了六个检测头,我再把onnx(float32)转成rknn(float16)时,模型精度分析发现模拟器simulator的余弦相似度和golden差不多,但是runtime(板端)测试时,这三个置信度输出的检测头余弦相似度特别低。实测时置信度低了很多(10%-40%)

尝试解决
初步怀疑是sigmoid的原因
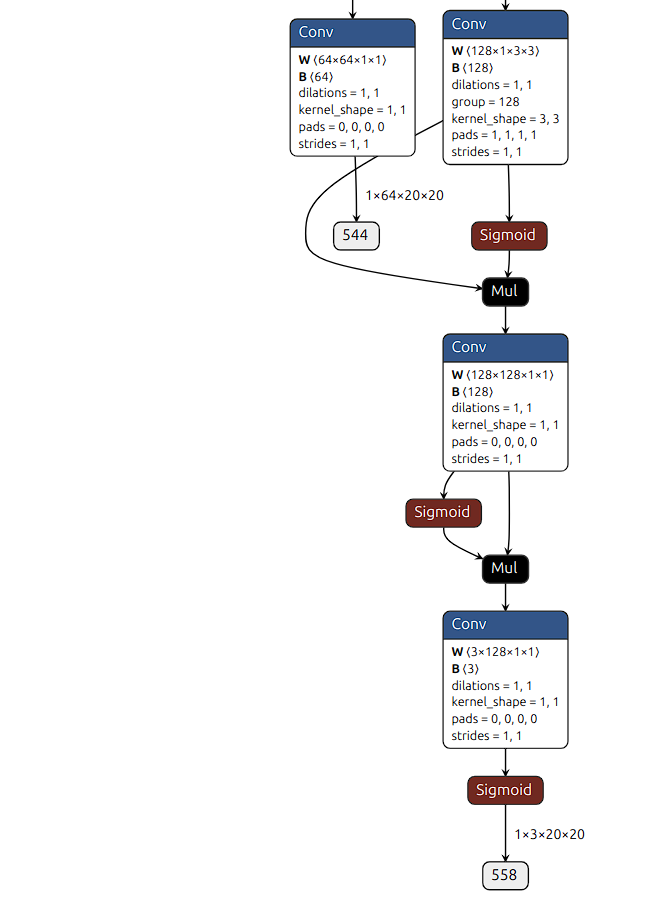
根据图2来看,YOLOv10 原本采用 SiLU 激活函数(SiLU(x) = x * Sigmoid(x)),在导出 ONNX 时会被拆解为 Sigmoid 和 Mul 算子。其他层由于残差连接和乘法操作(x * Sigmoid(x)),即使 Sigmoid 饱和(输出趋近于 1),仍能通过线性部分(x)保留有效信息,因此量化时影响较小。然而,置信度分支直接使用 Sigmoid 将输出压缩到 (0,1) 区间,在量化过程中容易因饱和而导致失真(如所有高分值被压缩到 0.99)。
个人觉得瑞芯微优化团队可能将 Sigmoid 替换为硬件友好但精度损失较大的近似计算,而量化团队未意识到该操作对置信度的严重影响,导致模型部署后性能下降。相比之下,其他层的 Sigmoid 因 SiLU 的残差结构而避免了完全失真,使得问题集中在置信度分支上。 (这里准备去看瑞芯微提供的NPU算子,很有可能是用了查表法实现非线性激活函数量化
【NPU sigmoid算子参考1】https://zhuanlan.zhihu.com/p/638006169
【NPU sigmoid算子参考2】https://blog.csdn.net/u011622208/article/details/123525286)
SiLU -> ReLU
问了业内人士并查看现有的YOLOv8成熟方案,大家的做法是把激活函数SiLU换成更适用于NPU硬件架构ReLU
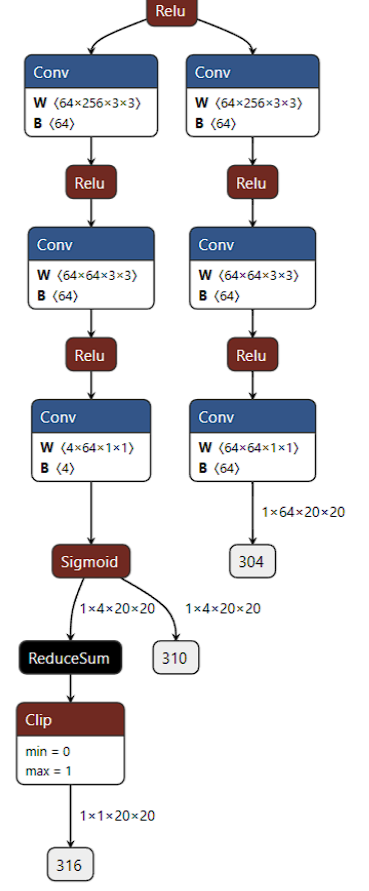
从激活函数上来看 背景:量化中的 scale 与 zero point
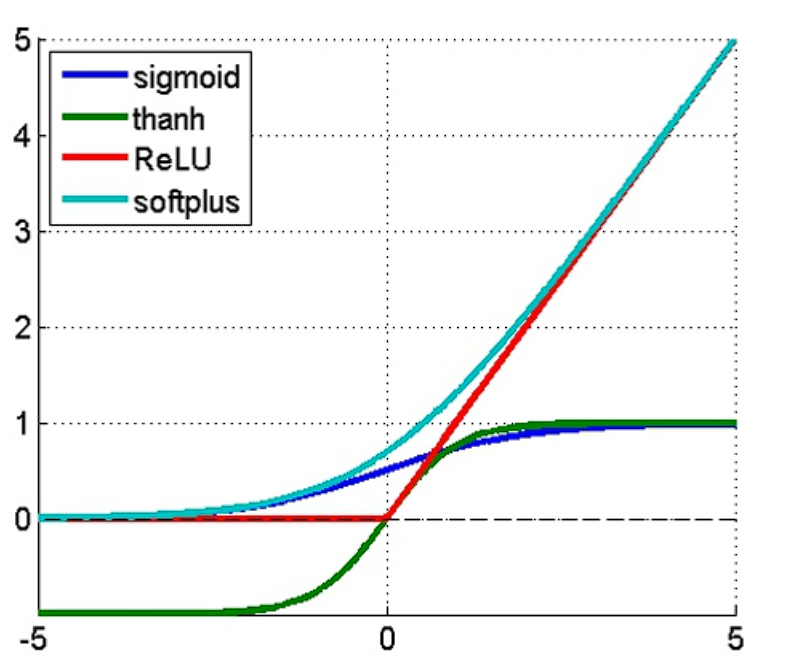
从精度上来看在小数特别小或特别大的时候,float16只有10个有效位,容易发生数值塌陷或者数值跳变。 sigmoid对输入的变化非常敏感float16在输入x很大(比如>6)或者很小(<-6)时,就几乎输出1或0了,导致梯度爆炸/塌陷。
在 RKNN 的 float16 模型中,虽然主干权重和激活是 float16,但在实际执行过程中某些通道还是会使用 scale和 zero point来辅助对齐。
尤其是在一些关键分支(如分类头、置信度 head)中:
1.如果模型输出值范围比较小,比如 sigmoid 后是 01,数值集中在 0.0010.1,float16 精度本身不够。
2.如果 scale 选得太大(默认自动选择整个输出 tensor 的 max/min ),就会导致:
-- 小数值被压得更小,近似于0,量化之后丢失;
-- 再解码回来就变成乱七八糟,甚至全0/全1。
这种误差不会在 PC 端模拟器中体现明显,因为模拟器往往保留 full-precision 中间值。但在板端 runtime 执行时,它使用的就是你最终编译后 quantize 的结构
解决方案
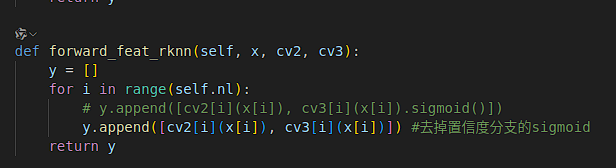
1.Sigmoid后处理 -> CPU
在yolov10的ultralytics里把置信度分支的sigmoid去掉:
在瑞芯微提供的yolov10中 ultralytics->nn->module->head.py->detect类下面
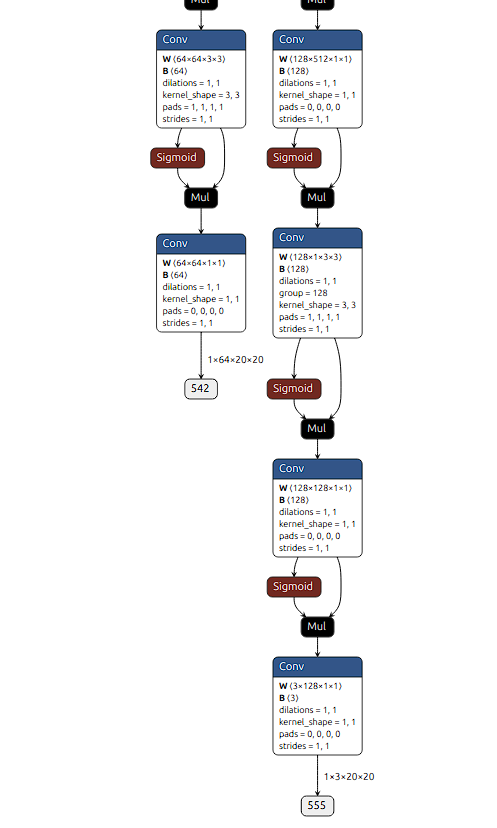
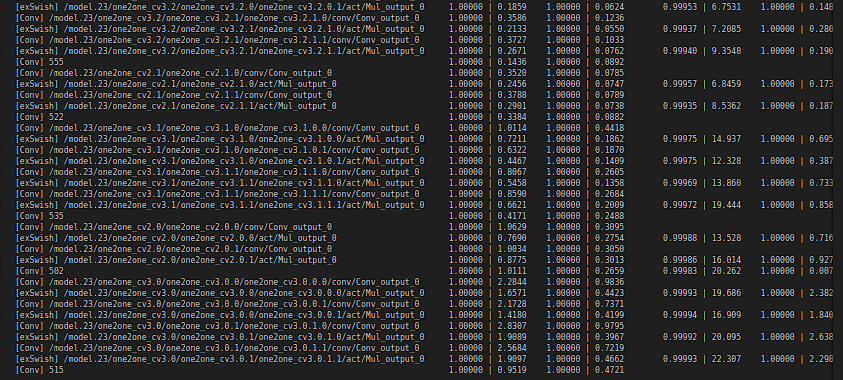
生成的onnx重新在runtime上跑,发现六个输出已经恢复正常
2.自定义算子
arm核上编译了一个cpu sigmoid算子(-10~10 lut),在后处理时调用,如果有用到simoid,可以查看每一层scale,然后根据不同的scale修改不同的lut。 测试下来,精度没有问题,推理速度也还不错。